
1. Introducción al concepto
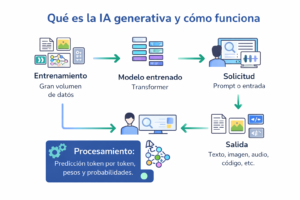
Qué es la IA generativa es una de las preguntas más repetidas en tecnología hoy. En términos simples, la IA generativa es una rama de la inteligencia artificial diseñada para crear contenido nuevo a partir de patrones aprendidos en grandes volúmenes de datos.
Ese contenido puede ser texto, imágenes, audio, vídeo, código o una mezcla de varios formatos.
A diferencia de un buscador tradicional, no se limita a recuperar una respuesta almacenada. En cambio, calcula cuál es la siguiente pieza más probable y útil según el contexto recibido. Por eso puede producir resultados nuevos en lugar de copiar bloques cerrados.
Cómo genera contenido un modelo
En un modelo de lenguaje, por ejemplo, el proceso básico consiste en predecir el siguiente token. Un token no siempre es una palabra completa. A veces puede ser una sílaba, una terminación o incluso un signo de puntuación.
Cuando un sistema genera una frase, no recupera un bloque fijo de memoria. Más bien, construye la salida paso a paso mediante operaciones matemáticas sobre vectores numéricos que representan relaciones entre conceptos, palabras y contextos.
A primera vista, esta idea parece simple. Sin embargo, escala de forma extraordinaria. Un modelo moderno puede entrenarse con miles de millones de ejemplos y ajustar cientos de miles de millones de parámetros.
Esos parámetros son valores internos que el sistema modifica durante el entrenamiento para mejorar sus predicciones. No son reglas escritas a mano ni una base de datos de respuestas. En realidad, son pesos numéricos distribuidos por una red neuronal que capturan regularidades estadísticas del lenguaje, de las imágenes o del sonido.
Por qué ha avanzado tan rápido
El salto reciente de la IA generativa no se explica por un único avance. Más bien, surge de la combinación de tres factores: más datos, más capacidad de cómputo y nuevas arquitecturas de red neuronal.
Además, el entrenamiento de estos sistemas requiere grandes clústeres de GPU o aceleradores especializados. Esos equipos deben estar interconectados para mover enormes volúmenes de datos con baja latencia. Sin esa infraestructura, los modelos actuales no podrían ajustarse en tiempos razonables.
Conviene añadir una precisión importante. Generar no equivale a comprender del mismo modo que lo hace un ser humano. Un modelo puede producir una explicación correcta sobre física cuántica y, al mismo tiempo, cometer errores básicos en otra tarea.
Esto ocurre cuando el contexto lo empuja hacia una respuesta estadísticamente plausible, pero falsa. En consecuencia, la IA generativa es muy potente como sistema de predicción estructurada. Aun así, exige supervisión, evaluación y un diseño de uso cuidadoso.
2. Cómo funciona la IA generativa con Transformers
La arquitectura que domina hoy la IA generativa es el Transformer, presentada en 2017 en el artículo Attention Is All You Need. Su aporte principal fue sustituir mecanismos secuenciales más lentos, como las redes recurrentes, por un sistema basado en atención.
Gracias a ello, el modelo puede evaluar qué partes de una secuencia son relevantes para interpretar cada elemento.
El papel de la atención
Si una frase dice “El servidor dejó de responder porque estaba saturado”, el modelo necesita relacionar “estaba saturado” con “servidor”, y no con “responder”. Ese tipo de dependencia a distancia es precisamente lo que la atención maneja bien.
En términos técnicos, cada token se transforma en tres vectores: query, key y value. Después, el sistema compara queries con keys para calcular qué tokens deben influirse entre sí. Finalmente, combina los values según esos pesos.
Ese cálculo ocurre en varias capas y en varios cabezales de atención al mismo tiempo. La multi-head attention permite que distintas partes del modelo capturen relaciones diferentes. Por ejemplo, puede seguir sintaxis, concordancia, contexto temático, referencias internas o patrones de estilo.
Después de cada bloque de atención, una red feed-forward ajusta la representación resultante. Además, todo ello se acompaña de normalización y conexiones residuales para estabilizar el entrenamiento.
Embeddings y posición
Antes de procesar el texto, el sistema convierte los tokens en vectores densos llamados embeddings. Un embedding es una representación numérica en la que términos relacionados quedan próximos en un espacio matemático de muchas dimensiones.
Así, palabras o fragmentos con usos parecidos terminan agrupados. Como el Transformer no procesa en orden secuencial estricto, necesita además una señal de posición. Esa información le permite saber qué token va antes y cuál va después. Para resolverlo, se añaden positional encodings.
Cómo aprende el modelo
El aprendizaje ocurre con un objetivo muy concreto: minimizar el error de predicción. Durante el entrenamiento, el modelo recibe secuencias incompletas y trata de adivinar el siguiente token.
Si falla, un algoritmo de optimización, normalmente una variante de descenso por gradiente, ajusta los parámetros internos para mejorar la siguiente iteración. Repetido billones de veces, ese proceso permite aprender gramática, relaciones semánticas, estructuras argumentativas y patrones de formato.
Después del preentrenamiento llega una fase de ajuste. En esa etapa entran técnicas como el fine-tuning supervisado y el aprendizaje por preferencias humanas. En la práctica, el modelo no solo aprende a continuar texto. También aprende a responder mejor a instrucciones, resumir, traducir, programar o mantener un tono útil.
Además, se añaden filtros y políticas para reducir respuestas dañinas, sesgos o alucinaciones. Aun así, estos problemas no desaparecen por completo.
Cómo genera una respuesta final
Cuando el modelo ya está entrenado, generar una respuesta implica una nueva serie de decisiones estadísticas. La salida no es fija. Depende de parámetros de inferencia como la temperatura, que controla cuánto riesgo toma el sistema al elegir tokens menos probables.
También influyen métodos como el muestreo top-k y top-p, que limitan el conjunto de candidatos. En general, un valor bajo produce respuestas más estables. Por el contrario, un valor alto genera resultados más variados, aunque también más impredecibles.

3. Aplicaciones actuales de la IA generativa
Texto y automatización documental
En texto, la IA generativa ya tiene usos claros en redacción asistida, búsqueda conversacional, análisis documental, atención al cliente, programación y síntesis de información.
En empresas, se utiliza para resumir contratos, generar borradores, clasificar incidencias o convertir lenguaje natural en consultas a bases de datos. Del mismo modo, en desarrollo de software los modelos pueden sugerir funciones, explicar errores y traducir código entre lenguajes.
Su utilidad no está en reemplazar por completo al profesional. Más bien, ayuda a reducir trabajo repetitivo y a acelerar tareas de primer borrador.
Generación de imágenes
La generación de imagen funciona con principios distintos, aunque relacionados. En lugar de predecir el siguiente token de texto, muchos sistemas actuales trabajan con modelos de difusión. El proceso comienza con ruido aleatorio y aprende a eliminarlo gradualmente hasta formar una imagen coherente.
Durante el entrenamiento, el modelo ve millones de imágenes con sus descripciones y aprende correspondencias entre conceptos visuales, composición, textura, iluminación y estilo. Luego, al recibir un prompt, guía el proceso de desruido hacia la escena pedida.
Esto explica por qué estos sistemas pueden producir una ilustración técnica, una fotografía sintética o una variación de un boceto. Sin embargo, también muestra sus límites. Entre ellos están las manos mal resueltas, el texto incrustado con errores, las geometrías improbables o los sesgos heredados de los datos de entrenamiento.
Para mitigarlos, se usan modelos más grandes, mejores conjuntos de datos, control por máscaras, edición localizada, generación por etapas y módulos de corrección.
Audio y voz
En audio, la IA generativa cubre tres frentes principales. El primero es texto a voz, donde un modelo convierte una secuencia escrita en una señal sonora natural. El segundo es voz a voz, capaz de transformar timbre, entonación o idioma mientras preserva parte de la prosodia.
El tercero es la generación musical y de efectos sonoros. Técnicamente, estos sistemas pueden operar sobre espectrogramas, tokens acústicos o representaciones latentes comprimidas.
El desafío no es solo producir sonido. También deben mantener continuidad temporal, respiración, ritmo y naturalidad.
Sistemas multimodales y RAG
La convergencia entre modalidades ya es una realidad. Un mismo sistema puede leer una imagen, describirla, responder preguntas sobre ella y generar texto o voz como salida.
Ese enfoque multimodal abre usos industriales concretos. Por ejemplo, permite inspección visual en fábricas con explicación automática, asistentes que interpretan manuales técnicos con diagramas, herramientas educativas que combinan imagen, subtítulos y narración, o buscadores capaces de entender documentos complejos con tablas y gráficos.
Ahora bien, el punto decisivo para cualquier aplicación real no es la demo, sino la integración. Para que un sistema generativo sea útil dentro de una organización, debe conectarse con fuentes fiables, registros internos, permisos de acceso, trazabilidad y métricas de calidad.
Por eso ganan peso técnicas como RAG (Retrieval-Augmented Generation). Con este enfoque, el modelo no responde solo desde sus parámetros, sino apoyándose en documentos externos recuperados en tiempo real. De este modo, se reduce el riesgo de inventar datos y se mejora la actualización de la información.

4. El futuro inmediato de la IA generativa
De chatbot a agente útil
En el corto plazo, la evolución de la IA generativa irá menos por “hablar mejor” y más por hacer tareas completas con mayor precisión. Eso significa modelos con mejor capacidad de razonamiento estructurado, uso de herramientas externas, acceso a bases de datos, ejecución de acciones y verificación automática de resultados.
En otras palabras, ahí está la diferencia entre un chatbot y un agente útil. No se trata de redactar una respuesta vistosa, sino de encadenar pasos correctos sobre información verificable.
Especialización y despliegue local
También veremos una mayor especialización. No todos los casos requieren un modelo gigante y generalista. En muchos entornos será más eficiente usar modelos más pequeños, entrenados o ajustados para dominios concretos como medicina, legal, finanzas, ingeniería o soporte técnico.
Además, estos modelos pueden desplegarse en servidores privados o incluso en dispositivos locales. Eso reduce latencia, coste y exposición de datos sensibles.
Eficiencia y optimización
Otro frente inmediato es la eficiencia. Durante los últimos años, entrenar modelos más grandes fue la estrategia dominante. Ahora la industria trabaja también en compresión, cuantización, mezcla de expertos y optimización de inferencia.
Por ejemplo, la cuantización reduce la precisión numérica de los pesos para ahorrar memoria y acelerar la ejecución sin perder demasiado rendimiento. De forma similar, la mixture of experts activa solo una parte del modelo en cada consulta, lo que mejora la relación entre coste y capacidad.
Regulación y supervisión
Habrá además más presión regulatoria y más exigencia de auditoría. Las preguntas ya no son solo técnicas. También afectan a derechos de autor, procedencia de datos, privacidad, seguridad, trazabilidad y responsabilidad por errores.
Por ello, en sectores críticos la IA generativa tenderá a operar bajo supervisión humana obligatoria, con registros de decisión y validación antes de ejecutar acciones relevantes.
Qué cambia para el trabajo humano
El escenario más probable para los próximos meses no es una sustitución total del trabajo intelectual, sino una redistribución de tareas. La máquina será cada vez más competente en borradores, clasificación, síntesis, traducción técnica, generación de variantes y automatización documental.
Mientras tanto, el valor humano se desplazará hacia la definición de objetivos, la revisión crítica, el contexto, el criterio y la responsabilidad final. Dicho de forma simple, la IA generativa ya sabe producir mucho. La diferencia seguirá estando en quién sabe pedir, comprobar y decidir mejor.



